I’ve noticed an increase in posts that note some surprising or insightful distinctions between intelligent agents (us) and large language models (LLMs) [1]. The arguments go something like this [2]:
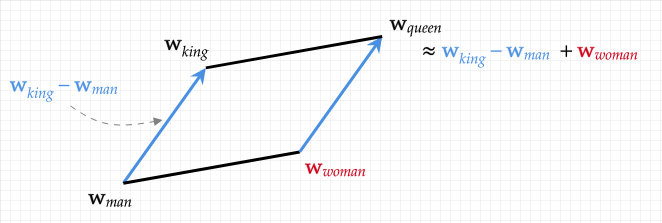
LLMs appear to be chatting with us. They appear to be drawing connections, synthesizing the mountain of information they've consumed with whatever prompt we just fed it. But under the hood, LLMs are actually doing nothing more than predicting the next chunk of text based on our prompt. They’re barely even predicting words, and certainly not concepts, sentences, or any other linguistic unit or abstraction humans might find intelligible. They’re predicting tokens—units like characters or parts of a word that use high-dimensional vectors called word embeddings that can represent semantic relationships. These can even be added, subtracted, or compared, revealing latent linguistic patterns (a well known example is: KING - MAN + WOMAN = QUEEN, or put another way: king is to man as ___ is to woman). But this semantic arithmetic can't possibly constitute understanding or intelligence. [3]

This all sounds off beat and novel to us, certainly a far cry from the natural language we’re familiar with in everyday interactions, conversations, word problems, emails, you name it. If the point is to distinguish between the token-crunching of LLMs and us, this line of argument is effective at appropriately pointing out how surprising and unintuitive LLMs’ linguistic fluency seems to be. But there are a couple things missing here:
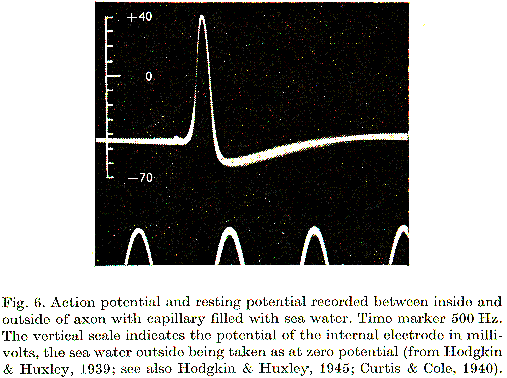
If LLM reasoning is so different and shocking to us, what are we actually comparing it to? What actually occurs if it's not something like a summing-up of a bunch of ones and zeros—neural spikes or action potentials, the all-or-nothing electrical signals that convey information from neuron to neuron? If we could pin down where the physical representation of the phrase “a bunch of ones and zeros” across our neural cells is, we might actually find that it looks a lot closer to tokens—and bits and bytes—than to the English alphabet.
It may be helpful to point out other unexpected examples of the ways our brains might mirror machine learning based approaches to information representation and processing. A couple illustrative examples would be:
So there are at least a couple of ways that LLMs might mirror the brain, but maybe not enough to convince anyone that there are significant broader similarities. Okay. Then perhaps it's worth exploring some of the stronger assertions made about LLMs shortcomings to see what we're left with. Here are five:
Assertion 1: LLMs lack genuine understanding. Many argue that LLMs merely simulate understanding through statistical pattern matching—they're stochastic parrots! But I'm not sure that we have any compelling evidence that human understanding is all that different. When we seem to understand something, aren't we pattern matching based on pre-wired circuits tuned on prior experience? What we should ask are questions about the quality and flexibility of pattern matching rather than whether or not it is ‘genuine’. And in the context of pattern matching, the question of 'genuine or not?' may not be a meaningful one to begin with. So perhaps we need a stronger definition of ‘understanding’ before we dismiss LLMs’ capabilities.
Assertion 2: LLMs don’t have embodied knowledge. True. LLMs clearly do not physically interact with the world, in contrast to human experience—see Jeff Hawkins' excellent book, A Thousand Brains. But a lot of human knowledge is acquired through language and abstract symbols where, for example, domain experts almost exclusively communicate in symbolic representation rather than embodied knowledge (think of musicians reading orchestral scores, economists and supply and demand curves, a linguist's syntax trees). Furthermore, our brains actually have no direct access to the world. Instead, it receives a flood of electrical signals from visual, auditory, olfactory, etc. pathways. And those electrical signals (think again of the many ones and zeros of action potentials, above) are computed and interpreted by our brains, blockaded within our skulls, constructing a model of the world out there. So these might be differences in degree rather than in kind.
Assertion 3: LLMs can’t update their knowledge in real-time. To my mind, this is one of the most important differences between LLMs and human knowledge. This difference speaks to how LLMs and brains differ in adjusting representations which is a different question than the way in which each represent knowledge. Methods like retrieval augmented generation (RAG) get us just a little bit closer to addressing this, and model updating is an active area of research in artificial intelligence right now. But if we're willing to grant that the underlying mechanisms of learning are similar, this may turn out to be a temporal difference—a difference in time-scale and frequency rather than of substance.
Assertion 4: LLMs don’t have conscious experience. This will feel like an even heavier hitting argument than the last and one that virtually everyone will immediately get. We know that we are conscious and cannot imagine how an LLM could have a similar experience. But consciousness is far from being a settled science—this area is still dominated by philosophy of mind, and a reading of heavy-weights like Daniel Dennett, David Chalmers, Patricia Churchland, or John Searle will yield four very different takes on what consciousness even is. Molecular biology has even less to say on this subject. Moreover, whether consciousness relates to intelligence or knowledge is also unclear. In fact, many examples of humans arriving at understanding point to unconscious processes (see Mlodinow's Subliminal or Kahnemann's Thinking Fast and Slow)—something Sigmund Freud observed over a century ago.
Assertion 5: LLMs hallucinate and make nonsensical mistakes humans would never make. Yes, well, maybe. Humans regularly make systematic errors in reasoning (Kahnemann’s Thinking Fast and Slow gives one of the most complete and insightful tours of all sorts of cognitive errors). So perhaps differences between LLM hallucinations and errors in human reasoning implicate architectural differences rather than more fundamental ones. And if that’s the case, the errors that we observe in each case might tell us more about the implementation details than about fundamental differences in processing.
Then on the other hand, there are many areas that LLMs are genuinely lacking. For example, LLMs do not have memory or temporal consistency. If you ask an LLM a question related to a previous conversation, it won’t have any memory of what you’re talking about—in humans we call this anterograde amnesia. Every interaction is a fresh conversation without any learning across sessions. They can struggle with physical causality. An LLM may be able to describe general relationships of cause-and-effect, but they lack even the physical intuition of an infant, the intuitive physics that a human of average intelligence just gets. They don’t have goal-directed behavior. They lack internal drives or motivation—an LLM will not lose interest in doing its taxes. LLMs don't integrate information across multiple modalities. Yes, multimodal models exist. But they don’t synthesize information across those modalities in the way that resembles what humans naturally do for visual, auditory, and tactile senses. [4]
There are plenty of differences between computation in the brain and in LLMs—e.g. how our brain compares what it receives to what it expects (i.e. bidirectional feedforward/feedback connections in the brain versus strictly feedforward LLMs), the networks of neurons that come ‘pre-wired’ at birth (e.g. visual processing pathways or language acquisition circuits). But of all those differences, the representation of knowledge and language may be one of the more superficial. And it may, on some meaningful level, be more a point of similarity or insight than of difference. We should not confuse surprising with unintelligent. At least not on these grounds.
